
David Alvarez-Melis
(he/him/his)
Assistant Professor, Harvard University (SEAS)
150 Western Av. Room 2-332, Allston MA 02134
[three initials]@seas.harvard.edu
Towards a Theory of Word Embeddings
A theoretical framework to understand the semantic properties of word embeddings.
TL;DR: Word embeddings have intriguing semantic properties (think King - Man + Woman = Queen). How do we make sense of them? Cognitive Science and Metric Recovery yield a possible answer.
Abstract
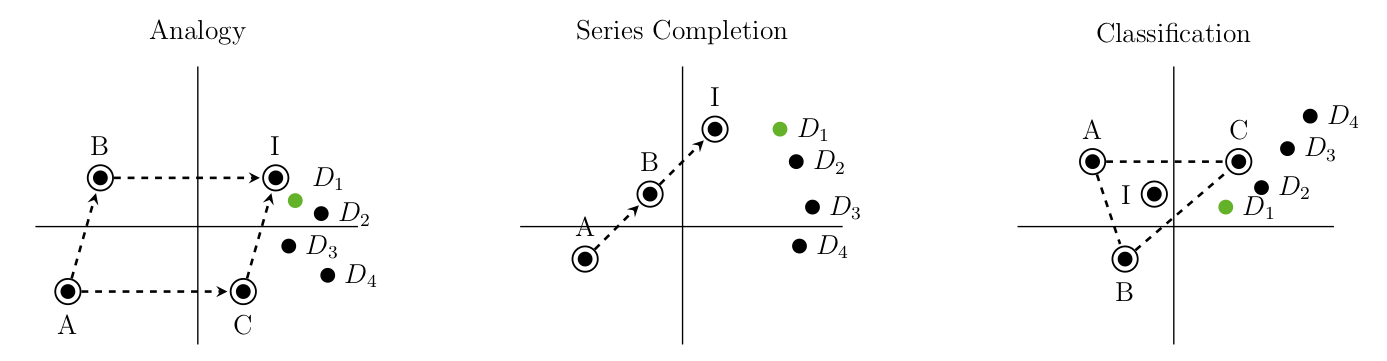
Continuous word representations have been remarkably useful across NLP tasks but remain poorly understood. We ground word embeddings in semantic spaces studied in the cognitive-psychometric literature, taking these spaces as the primary objects to recover. To this end, we relate log co-occurrences of words in large corpora to semantic similarity assessments and show that co-occurrences are indeed consistent with an Euclidean semantic space hypothesis. Framing word embedding as metric recovery of a semantic space unifies existing word embedding algorithms, ties them to manifold learning, and demonstrates that existing algorithms are consistent metric recovery methods given co-occurrence counts from random walks. Furthermore, we propose a simple, principled, direct metric recovery algorithm that performs on par with the state-of- the-art word embedding and manifold learning methods. Finally, we complement recent fo- cus on analogies by constructing two new inductive reasoning datasets—series completion and classification—and demonstrate that word embeddings can be used to solve them as well.

Relevant Publications:
- Hashimoto, Alvarez-Melis and Jaakkola. “Word, graph and manifold embedding from Markov processes”, NIPS 2015 Workshop on Nonparametric Methods for Large Scale Representation Learning.
- Hashimoto, Alvarez-Melis and Jaakkola. “Word Embeddings as Metric Recovery in Semantic Spaces”, TACL’16.