
David Alvarez-Melis
(he/him/his)
Assistant Professor, Harvard University (SEAS)
150 Western Av. Room 2-332, Allston MA 02134
[three initials]@seas.harvard.edu
Robustly Interpretable Machine Learning
Bridging the gap between model expressiveness and transparency
Abstract
(Under construction)
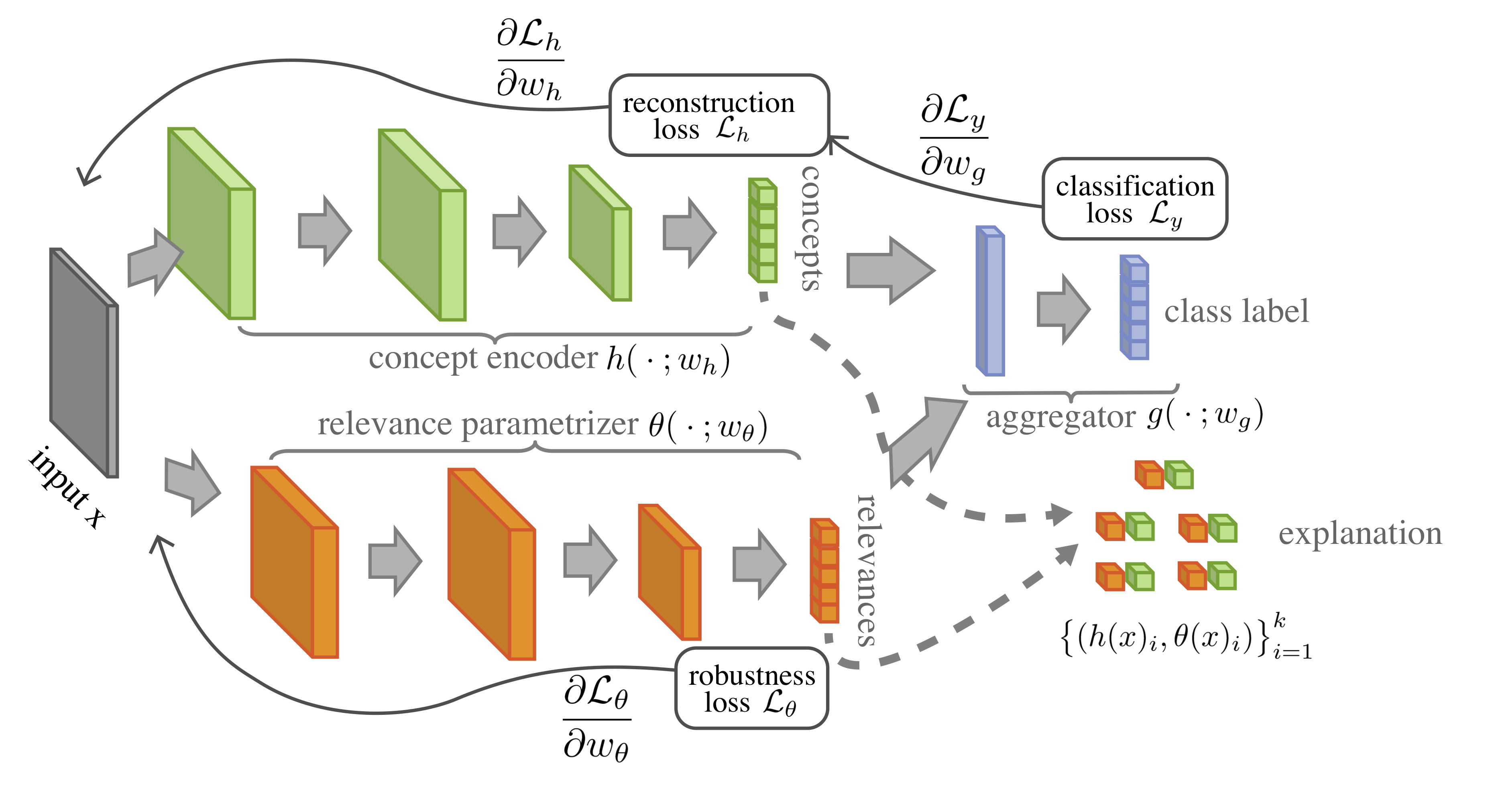
From Extrinsic to Intrinsic Explanations: Self-Explaining Neural Networks
Most recent work on interpretability of complex machine learning models has focused on estimating a posteriori explanations for previously trained models around specific predictions. Self-explaining models where interpretability plays a key role already during learning have received much less attention. We propose three desiderata for explanations in general – explicitness, faithfulness, and stability – and show that existing methods do not satisfy them. In response, we design self-explaining models in stages, progressively generalizing linear classifiers to complex yet architecturally explicit models. Faithfulness and stability are enforced via regularization specifically tailored to such models. Experimental results across various benchmark datasets show that our framework offers a promising direction for reconciling model complexity and interpretability.
Relevant Publications:
- Alvarez-Melis and Jaakkola. “A Causal Framework for Explaining the Predictions of Black-Box Sequence-to-Sequence Models”, EMNLP 2017.
- Alvarez-Melis and Jaakkola. “On the Robustness of Interpretability Methods”, WHI@ICML 2018.
- Lee, Alvarez-Melis and Jaakkola. “Game-theoretic Interpretability for Temporal Modeling”, FAT/ML@ICML2018.
- Alvarez-Melis and Jaakkola. “Towards Robust Interpretability with Self-Explaining Neural Networks”, NeurIPS 2018.
- Lee, Alvarez-Melis and Jaakkola. “Towards Robust, Locally Linear Deep Networks”, ICLR 2019.
- Lee, Jin, Alvarez-Melis and Jaakkola. “Functional Transparency for Structured Data: a Game-Theoretic Approach”, ICML 2019.
- Alvarez-Melis, Daumé III, Wortman Vaughan, Wallach. “Weight of Evidence as a Basis for Human-Oriented Explanations”, HCML @ NeurIPS 2019.